
“Obviamente, muitas pessoas estão céticas quanto à construção de uma IA poderosa em breve, e algumas duvidam que ela sequer seja construída algum dia. Acredito que isso pode acontecer já em 2026, embora também haja a possibilidade de levar muito mais tempo”.
Dario Amodei (Machine Loving Grace)
Dezembro de 2025. Em meio ao turbilhão de um denso relatório em PDF, um oceano de 800 mil documentos digitais e o fluxo incessante de uma videoconferência, uma inteligência artificial invisível rege a sinfonia do trabalho. Responde a indagações com a velocidade do pensamento, tece o relatório final com maestria e, num gesto simultâneo, garante o bilhete de trem para o próximo compromisso. O que hoje se configura como uma demonstração de virtuosismo tecnológico poderá, em um futuro bem próximo, pintar a tela do cotidiano corporativo. A efervescência do primeiro semestre de 2025 já prenuncia essa mudança: a OpenAI nos presenteou com o GPT-4.1, um modelo de linguagem capaz de absorver bibliotecas especializadas inteiras em uma única sessão, cortesia de uma janela de contexto de um milhão de tokens. O Google, por sua vez, já mira a estratosfera dos dois milhões com o Gemini 2.5.
Entretanto, a magnitude bruta não detém mais o cetro da decisão. Paralelamente, mentes brilhantes em laboratórios experimentam com arquiteturas agentivas, onde modelos especializados colaboram em harmonia, operam intrincadas camadas de software e devolvem, de forma autônoma, suas reflexões aos artífices humanos. Os primeiros vislumbres práticos, como o “Operator” da OpenAI e o ambicioso arcabouço multiagente “Kiro” da Amazon, sinalizam que essa abordagem transcende o mero exercício de marketing. Contudo, vozes experientes ecoam um alerta: um “escritório povoado por aprendizes algorítmicos”, ágeis na execução, mas nem sempre dotados da necessária confiabilidade.
Nesse panorama dinâmico, este artigo se propõe a desvendar quais avanços se mostram palpáveis na segunda metade de 2025, onde incrementos graduais são a tônica esperada e quais promessas ainda residem no reino da especulação. A questão central que nos guia é se os próximos seis meses testemunharão, de fato, a transição de uma inteligência artificial meramente assistente para uma genuinamente atuante – ou se a tecnologia permanecerá enredada em teias regulatórias, econômicas e metodológicas.
A Incansável Busca pelo Contexto
A OpenAI crava um novo marco com o GPT-4.1: um milhão de tokens processados sem qualquer degradação na qualidade da resposta, e um custo por token 26% menor – um eloquente sinal de que a eficiência do modelo e a profundidade do contexto não são mais forças opostas.
Os três modelos em questão ostentam a capacidade de processar até um milhão de tokens de contexto – a matéria-prima textual, visual ou audiovisual que alimenta o prompt. Um salto gigantesco em relação ao limite de 128 mil tokens do GPT-4o. “Todos os três modelos podem processar até um milhão de tokens de contexto – o texto, imagens ou vídeos incluídos em um prompt. Isso é muito mais do que o limite de 128.000 tokens do GPT-4o. “Treinamos o GPT‑4.1 para lidar de forma confiável com informações em todo o comprimento de contexto de 1 milhão”, afirma a OpenAI em uma postagem anunciando os modelos.
“Também o treinamos para ser muito mais confiável do que o GPT‑4o na identificação de texto relevante e na ignorância de elementos de distração em comprimentos de contexto longos e curtos.” O GPT 4.1 também é 26% mais barato que o GPT-4o, uma métrica que se tornou mais importante após a estreia do modelo de IA ultraeficiente da DeepSeek”.
The Verge
O Google não tarda em responder com o Gemini 2.5, mencionando abertamente a promessa de “2 milhões de tokens em breve”, com os primeiros beta testers já reportando incursões bem-sucedidas com 1,2 milhão.
Essas janelas de contexto cada vez mais amplas estão redesenhando as fronteiras dos produtos: em vez de intrincados pipelines de recuperação de informação, vastos oceanos de conhecimento precisarão fluir diretamente para dentro da sessão. Paralelamente, a pressão para domar as alucinações em diálogos extensos se intensifica – um desafio que estudos recentes descrevem como um “problema de fragmentação”. A indústria contra-ataca com prompts hierárquicos, memórias distribuídas e técnicas de amostragem por compressão semântica, ferramentas que provavelmente encontrarão seu lugar em SDKs comerciais até o final do ano.
Sistemas Agentivos: A Transição de Assistente a Executor
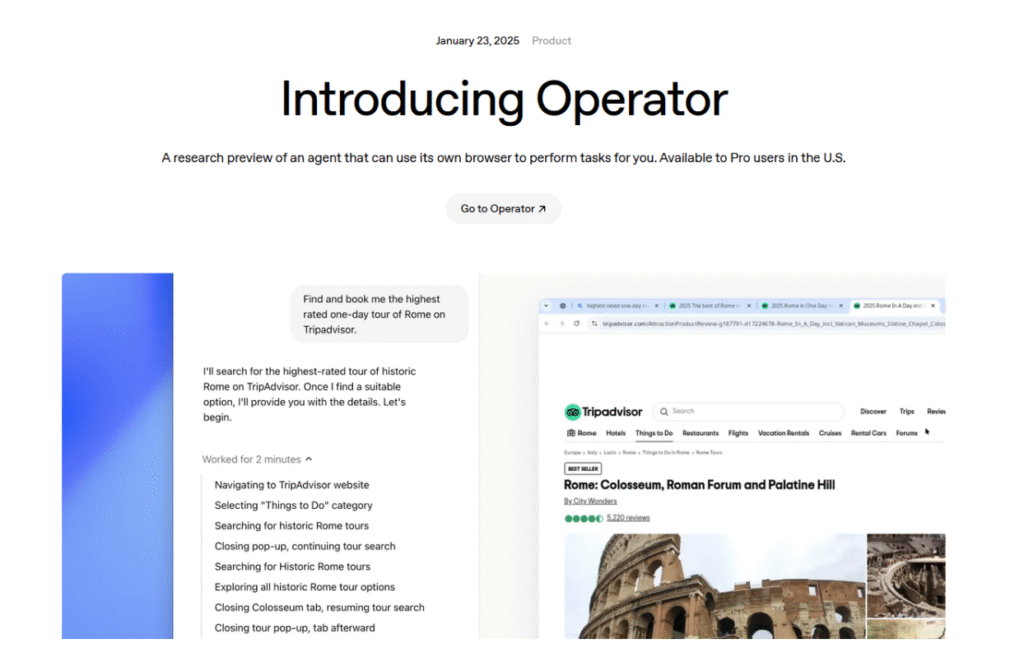
Em janeiro, a OpenAI nos brindou com o “Operator” – um agente digital capaz de navegar na web e em desktops, adquirir ingressos para eventos e preencher formulários com desenvoltura. A Amazon responde à altura com o “Kiro”, um arcabouço multiagente projetado para a produção de código em tempo real; documentos internos acenam para o final de junho como a janela mais otimista para uma primeira demonstração.

A Microsoft, por sua vez, planeja transformar o Copilot Studio em uma plataforma de agentes até setembro, onde desenvolvedores poderão empacotar seus próprios microagentes como blocos de construção reutilizáveis. Em uma análise amplamente citada, a IBM adverte que agentes autônomos “não concedem uma licença para automação irrestrita” e devem permanecer integrados em fluxos de trabalho com pontos de transição bem definidos. A experiência prática ecoa essa cautela: projetos piloto em departamentos financeiros revelam que a supervisão humana, inicialmente, reduz custos, pois as potenciais falhas são identificadas em seus estágios iniciais.
E embora Hay esteja esperançoso quanto ao potencial para o desenvolvimento agentivo em 2025, ele vê um problema em outra área: “A maioria das organizações não está pronta para agentes. O que será interessante é expor as APIs que vocês têm em suas empresas hoje. É aí que o trabalho empolgante acontecerá. E isso não se trata de quão bons os modelos serão. Trata-se de quão preparadas para empresas vocês estão.”
IBM
A Efervescente Revolução da Mídia Multimodal
A linha que outrora separava texto e vídeo se esvai. Protótipos de pesquisa pioneiros agora conseguem gerar sequências de filmes animados coerentes de um minuto a partir de um único comando textual.

Equipes de código aberto como a FramePack demonstram que clipes de 60 segundos agora rodam suavemente em GPUs de consumidor equipadas com 6 GB de VRAM. Os modelos de 13 trilhões de parâmetros que chegam ao mercado, como o LTX da Lightrick, reduzem os tempos de renderização em um fator de 30. A disseminação em larga escala agora depende menos do poder computacional bruto e mais de intrincadas questões de licenciamento e direitos autorais – pontos que a regulamentação da UE aborda com ênfase.
A Cognição das Ferramentas e os Protocolos Abertos
A OpenAI orquestra uma fusão elegante entre suas APIs de chat, assistentes e chamada de função em uma única “Responses API” – incorporando busca na web integrada, interpretador de código e análise de tabelas. Em paralelo, a Anthropic impulsiona o Model Context Protocol (MCP) como um padrão aberto, permitindo que agentes estabeleçam áreas de memória compartilhada. Essa convergência simplifica o processo de desenvolvimento; startups relatam ciclos de iteração 40% mais curtos desde a introdução dessas chamadas multifuncionais.
As Imposições da Realidade Regulatória
Em 2 de agosto de 2025, as obrigações de governança do AI Act da UE para modelos de propósito geral entrarão em vigor. Os fornecedores deverão divulgar informações essenciais sobre seus dados de treinamento e aderir a um código de conduta – “prova central de conformidade”, nas palavras da Comissão. Apesar das tentativas das empresas de tecnologia de suavizar algumas cláusulas, Bruxelas até agora se mantém inabalável. O resultado: a partir do segundo semestre de 2025, cada lançamento de produto europeu será acompanhado por relatórios de transparência; alguns fornecedores dos EUA cogitam lançar modelos específicos para a UE com um selo de parâmetro distinto.
Personalização: Da Vastidão do Contexto à Memória Perene
Talvez a transformação mais radical nos próximos meses não resida na contagem de parâmetros, mas sim na capacidade dos modelos de linguagem de “lembrar” usuários individuais. Em abril, a OpenAI apresentou uma “memória estendida” que transcende a simples armazenagem de fatos explícitos, analisando todo o histórico de conversas e incorporando-o em novas respostas – oferecendo, inclusive, a opção de reescrever essas memórias para otimizar buscas na web e refinar consultas.

Essa inovação desloca a personalização de um ajuste fino estático de “instrução personalizada” para uma memória dinâmica que opera como um arquivo vetorial privado: frases relevantes de sessões passadas são vetorizadas, ponderadas de acordo com sua proximidade semântica e injetadas em cada prompt como uma representação latente adicional. Em conjunção com janelas de contexto que ultrapassam a marca de um milhão de tokens, emerge algo semelhante a uma base de conhecimento contínua e individualmente curada – uma distinção já evidente em testes, onde o ChatGPT automaticamente reconhece preferências de estilo pessoal ou projetos anteriores sem que o usuário precise mencioná-los novamente.
A competição também acelera o passo: o Google integrou uma função “Recall” ao Gemini Advanced, capaz de resumir conversas anteriores e retomá-las automaticamente, se necessário. A Anthropic adota uma postura mais cautelosa, permitindo o armazenamento de “resultados de trabalho”, mas deliberadamente evitando a criação tácita de perfis de personalidade – um compromisso particularmente apreciado em setores regulamentados. A Meta, por sua vez, aposta em pesos abertos: com o Llama 3.2, um estilo de linguagem pessoal pode ser treinado no AWS Bedrock ou em GPUs locais por meio de um adaptador LoRA em poucas horas – a um décimo do custo das tradicionais sessões de ajuste fino.
Portanto, é provável que duas vertentes de modelos emerjam – uma memória na nuvem com opções granulares de adesão para mercados abertos e minimodelos do lado do cliente, mantendo preferências sensíveis criptografadas no dispositivo do usuário. Ambas as abordagens, em última análise, perseguem o mesmo objetivo: uma IA que não apenas compreende o que é dito, mas também quem está falando – e, assim, transforma o diálogo de uma interação isolada em uma colaboração contínua e pessoal.
Resultados Preliminares ao Final do Trimestre
A dinâmica observada aponta para o aumento de contexto e os sistemas agentivos como os principais motores da inovação na segunda metade do ano, enquanto a renderização de vídeo multimodal, apesar de seu fascínio, ainda luta contra as limitações da infraestrutura e do arcabouço legal. Paralelamente, a regulamentação da UE impõe transparência aos grandes laboratórios sem, contudo, desacelerar visivelmente o ritmo do desenvolvimento – pelo menos até que as penalidades financeiras entrem em pleno vigor em 2026.
- Lançamento do GPT-5 com processamento totalmente integrado de voz, imagem e áudio no outono: ≈ 95% (a maior parte já anunciada)
- Janelas de contexto públicas de 2 milhões de tokens em ofertas de nuvem até dezembro: ≈ 85% (fonte: blog.google)
- Agentes de escritório semiautônomos amplamente disponíveis (Operator, Kiro, Copilot) em ambientes produtivos: ≈ 65% (ainda muitos obstáculos, mas avanços significativos)
- Vídeos de IA de um minuto com personagens consistentes para campanhas de marketing: ≈ 55%
- LLMs no dispositivo < 10 B parâmetros em smartphones de ponta: ≈ 40% (tendência indireta de roteiros de chips, sem anúncio oficial)
- APIs de ferramentas padronizadas (Responses API / MCP) como padrão da indústria: ≈ 85%
Em Síntese
Os próximos seis meses serão cruciais para definir se a IA trilhará o caminho da maturidade, deixando de ser um mero assistente dialógico para se tornar um verdadeiro parceiro de projetos colaborativos. Se a estabilização de milhões de contextos se concretizar, pesquisa, planejamento e execução se fundirão em uma única e fluida interação. Ao mesmo tempo, a ascensão dos sistemas baseados em agentes está inexoravelmente permeando os processos de trabalho cotidianos, desde a submissão de código até os lançamentos financeiros. A regulamentação, por sua vez, estabelece um marco de clareza sem, no entanto, estrangular o motor da inovação.
Será que a segunda metade do ano nos presenteará com o grande salto? As evidências sugerem que presenciaremos o surgimento dos primeiros agentes multimodais escaláveis, capazes de aprender, decidir e agir em tempo real – ainda que sob o olhar vigilante das equipes de conformidade e de um público que clama por transparência de dados. A questão mais intrigante que permanece em aberto é, portanto: 2026 será o ano em que as pessoas não apenas comissionarão agentes, mas também lhes conferirão responsabilidade genuína?